
Employing deep learning to capture and characterise natural behaviours in Bumblebees
Summary
Insects, and bees in particular are recognised as the primary animal pollinator of food crops worldwide. Current methods employed to monitor health in bees are not only resource intensive but often also involve harming the bees themselves. My masters thesis focused on tackling this problem with the aim of developing a resource efficient, non-destructive assay for pesticide exposure using videos recorded with a smartphone camera. The behaviour of bumblebees under two treatments: exposed to pesticides or control were recorded and individual video frames were manually annotated. This served as training data for the pose estimation network. The network outputs machine labelled bodyparts for every video frame provided positional information which represents the trajectory of bodyparts in space and time. This rich spatiotemporal data was then fed into a pre-processing pipeline which involved engineering the features of speed, displacement and angle change for the labelled bodyparts. Dimensionality reduction was applied followed by an unsupervised learner to identify clusters of similar behavioural patterns. Ideally, the clusters reflect naturalistic behaviours such as resting, locomotion, and feeding which would translate to behavioural profiles defined by time spent performing each of the behaviours for each treatment. These behavioural profiles provide the defining feature for a machine learning classifier which could replace traditional bioassays for pesticide exposure. Despite performing well on the labelled training frames, the pose estimation network did not display transferrability in labelling the variety of poses the bumblebees exhibited. The lack of dependable input data meant that the effectiveness of downstream analysis were hindered and this was reflected in the lack of meaningful behavioural segmentation by the unsupervised classifier.
How it works
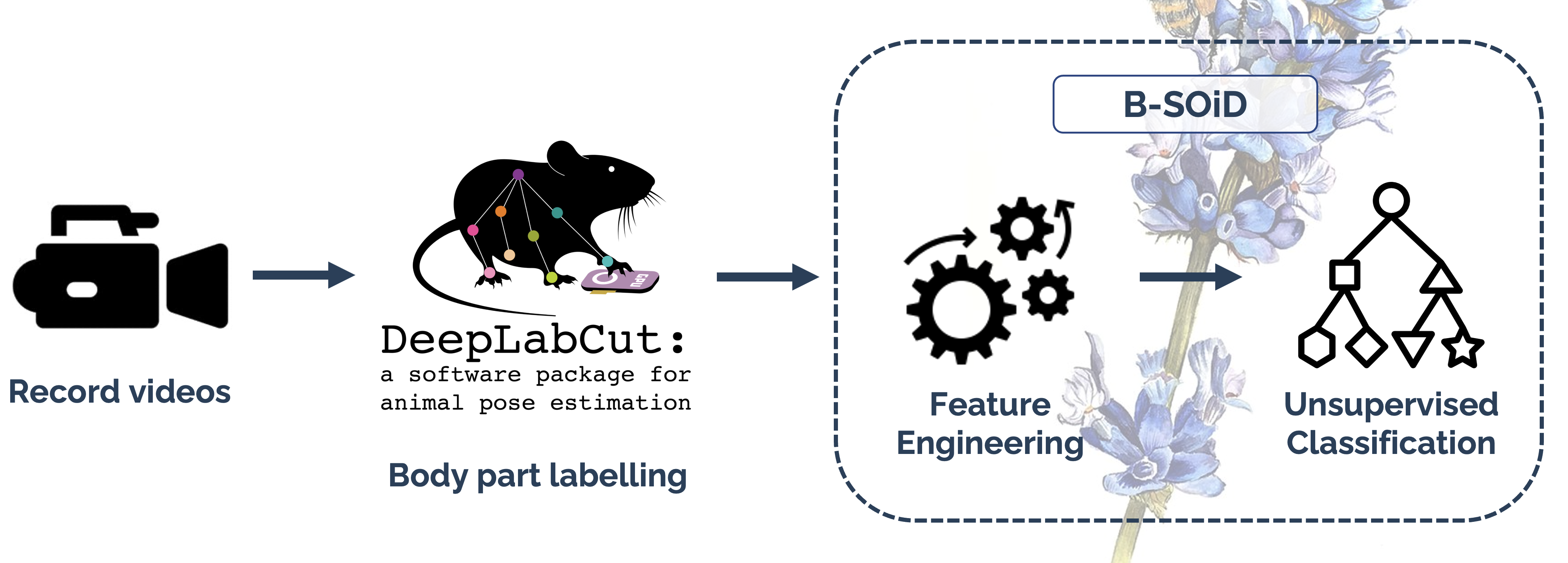
DeepLabCut is a transfer learning application built upon imagenet object recognition networks. Given labelled input data, this enables the identification and location of body parts for any animal organism. A total of 250 frames were annotated and trained over 1.45m iterations reaching a loss of ≈0.0008. When evaluated on the annotated images the train and test error were 1.74 and 10.13 respectively. However upon inference, achieving similar confidence with the unseen video footage proved challenging.

Results

Likelihood values confer the certainty of pose estimation for a given body part on a given frame. Due to the nature of pose estimation and visual occlusion, there are bound to be a peak of low as well as high confidence frames. It follows that for a given body part in a given video, likelihood values follow a bimodal distribution. The inflexion point in this distribution defined the threshold for each bodypart. The data below is reflective of 8 data files representing pose estimation in 8 videos and shows the mean percentage of frames in a video where the given bodypart was labelled with a likelihood value below the given threshold.
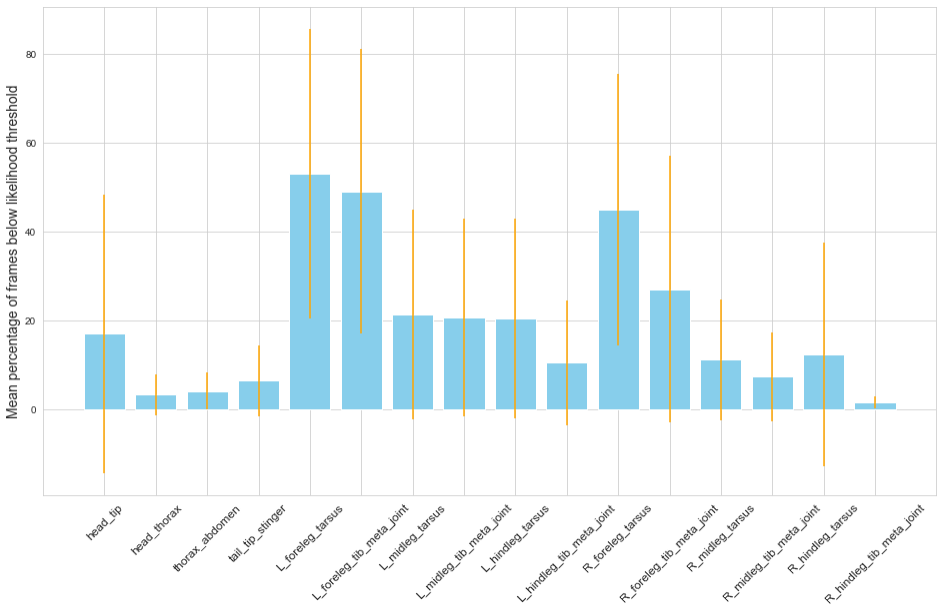
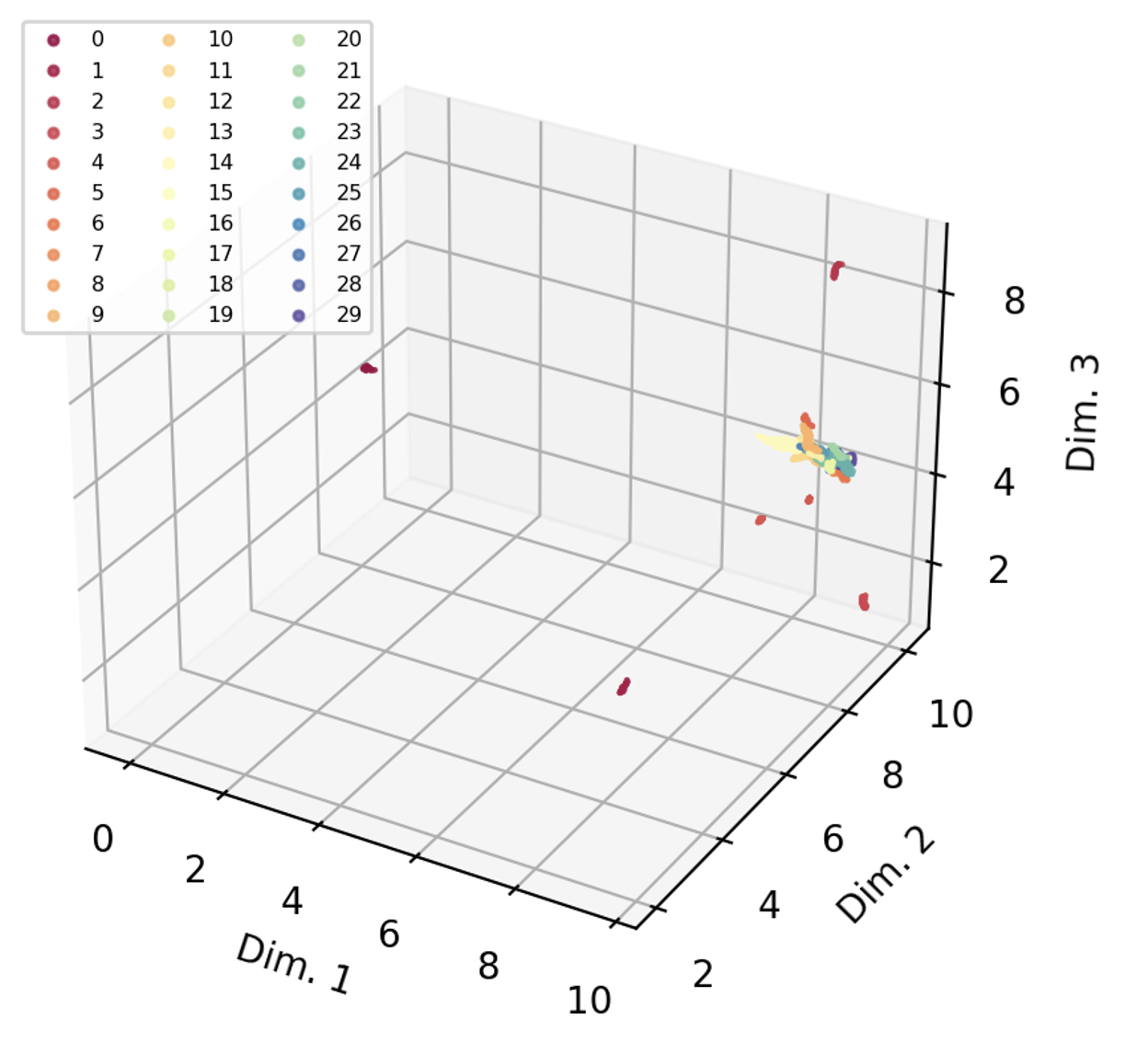
Given the substantial proportion of low confidence frames, particularly in the forelegs, it was unsurprising that behavioural segmentation using unsupervised classification techniques did not yield satisfying results. 30 behavioural groups were identified and most group assignments contained more than one stereotyped behaviour.
Conclusions
The lack of representative pose estimation data bottlenecked any further possibility for accurate behavioural segmentation. Although Mathis et al., (2018) suggest that 200 labelled frames suffice for accurate pose estimation, Hsu and Yttri, (2021) labelled over 7800 frames and it is likely that the network would have benefitted from more high-quality labelled data. Upon visual inspection of labelled videos there is noticeable uncertainty in labelling due to climbing behaviour which causes occlusion pointing towards potential improvements in the video recording setup. Further, to optimise behavioural segmentation, video framerate directly impacts the temporal resolution of the pose estimation data. Given the smartphone camera setup, there were limitations on maximal resolution and framerate leaving space for further optimisation on the table.
References
Hsu, A.I. and Yttri, E.A. (2021). B-SOiD, an open-source unsupervised algorithm for identification and fast prediction of behaviors. Nature Communications, 12(1). doi:10.1038/s41467-021-25420-x.
Mathis, A., Mamidanna, P., Cury, K.M., Abe, T., Murthy, V.N., Mathis, M.W. and Bethge, M. (2018). DeepLabCut: markerless pose estimation of user-defined body parts with deep learning. Nature Neuroscience, [online] 21(9), pp.1281–1289. doi:10.1038/s41593-018-0209-y.